Hadoop Streaming Read Number of Reducers Getenv
The Why and How of MapReduce
![]()
When do I need to use MapReduce? How tin I translate my jobs to Map, Combiner, and Reducer?

MapReduce is a programming technique for manipulating large data sets, whereas Hadoop MapReduce is a specific implementation of this programming technique.
Following is how the procedure looks in general:
Map(s) (for private clamper of input) ->
- sorting individual map outputs ->
Combiner(southward) (for each individual map output) ->
- shuffle and sectionalization for distribution to reducers ->
- sorting individual reducer input ->
Reducer(southward) (for sorted data of group of partitions) Hadoop's MapReduce In General
Hadoop MapReduce is a framework to write applications that process enormous amounts of data (multi-terabyte) in-parallel on big clusters (thousands of nodes) of article hardware in a reliable, fault-tolerant way.
A typical MapReduce job:
- splits the input data-set up into independent data sets
- each private dataset is processed in parallel by the map tasks
- then the framework sorts the outputs of maps,
- this output is then used equally input to the reduce tasks
In general, both the input and the output of the job are stored in a file-organization.
The Hadoop MapReduce framework takes care of scheduling tasks, monitoring them, and re-execution of the failed tasks.
Generally, the Hadoop's MapReduce framework and Hadoop Distribution File System (HDFS) run on the same nodes, which ways that each node is used for calculating and storage both. The do good of such a configuration is that tasks can exist scheduled on the nodes where data resides and thus results in loftier aggregated bandwidth across the cluster.
The MapReduce framework consists of:
- a unmarried principal
ResourceManager(Hadoop YARN), - i worker
NodeManagerper cluster-node, and -
MRAppMasterper awarding
The resources manager keeps rails of compute resources, assigns them to specific tasks, and schedules jobs across the cluster.
In club to configure a MapReduce task, at minimum, an awarding specifies:
- input source and output destination
- map and reduce office
A task along with its configuration is so submitted by the Hadoop's task customer to YARN, which is then responsible for distributing it beyond the cluster, schedules tasks, monitors them, and provides their condition back to the job client.
Although the Hadoop framework is implemented in Coffee, MapReduce applications demand not be written in Java. We tin use mrjobs Python package to write MapReduce jobs that tin can be run on Hadoop or AWS.
Inputs And Outputs Of MapReduce Jobs
For both input and output, the data is stored in key-value pairs. Each key and value form has to be serializable by the MapReduce framework and thus should implement the Writable interface. Autonomously from this, the key course needs to implement WritableComparable the interface equally well which is required for sort mechanism.
The Mapper
A Mapper is a task which input key/value pairs to a set of output cardinal/value pairs (which are and so used past farther steps). The output records do not need to be of the same type as that of input records, besides an input pair may be mapped to zero or more than output pairs.
All values associated with a given output key are subsequently grouped by the framework and passed to the Reducer(south) to determine the last output. The Mapper outputs are sorted and so partitioned per Reducer. The total number of partitions is the same as the number of reduce tasks for the job.
Shuffle & Sort Phases
The output of private mapper output is sorted by the framework.
Before feeding data to reducers, the data from all mappers is partitioned past some grouping of keys. Each division contains data from one or more than keys. The data for each partition is sorted past keys. The partitions are and so distributed to reducers. Each reducer input data is data from i or more partitions (generally 1:one ratio).
The Reducer
A Reducer reduces a gear up of intermediate values (output of shuffle and sort phase) which share a key to a smaller set of values.
In the reducer stage, the reduce method is called for each <key, (list of values)> pair in the grouped inputs. Notation that the output of Reducer is not sorted.
The correct number of reducers are generally between 0.95 and 1.75 multiplied by <no. of nodes> * <no. of maximum containers per node>.
The Combiner
We can optionally specify a Combiner (know every bit local-reducer) to perform local assemblage of the intermediate outputs, which helps to cut downward the amount of data transferred from the the Mapper to Reducer. In many cases, the same reducer code can be used every bit a combiner as well.
Let's look at a simple example
Allow'southward look at a simple case of counting give-and-take frequencies. Consider the following mapper.py file:

and following reducer.py file:

Nosotros tin locally exam them as:
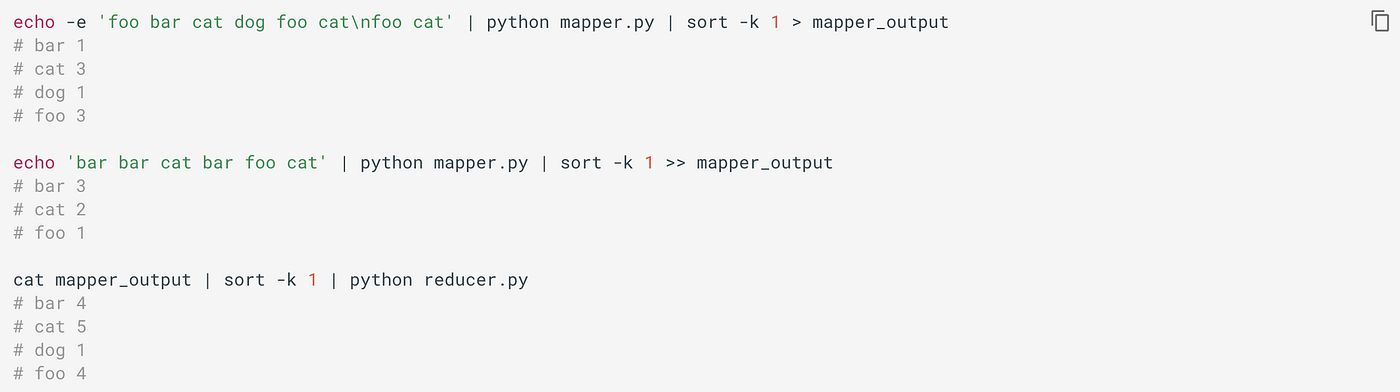
But Expect! The previous implementation has a trouble…
The previous mapper code is memory intensive equally it has to maintain a dictionary of the frequency of all of the unique words nowadays chunk of input for each individual mapper. If memory is a business organisation fifty-fifty for dict involving individual chunks of inputs, and then the improve fashion is to allow it simply print each word equally nosotros see (with its frequency every bit i). For example,

Now, permit'due south apply new mapper with the same input information:

If it helps, we tin can as well apply a combiner (same equally reducer code) for local aggregation from each mapper output.

Details on Partitioner And Comparator
A Partitioner partitions the data, which it does past substantially partitioning the "key space".
Partitioner controls the sectionalisation of the keys of the intermediate map-outputs. The key (or a subset of key) is used to derive the partition, typically past a hash part. The total number of partitions is the same every bit the number of reduce tasks for the job. Hence this controls which of the m reduce tasks the intermediate key (and hence the record) is sent to for reduction.
HashPartitioner is the default Partitioner. You would need to use different partitioner (or your custom one) if you demand to partition data by multiple keys.
Hadoop has a library class, KeyFieldBasedPartitioner which allows the MapReduce framework to sectionalisation the map outputs based on certain key fields, not the whole keys. For case, -D mapreduce.partition.keypartitioner.options=-k1,2.
We can control the grouping by specifying a Comparator .
Hadoop has a library course, KeyFieldBasedComparator, that provides a subset of features provided by Unix/GNU sort part. For example, -D mapreduce.partition.keycomparator.options=-k2,2nr.
The DistributedCache
The DistributedCache, provided by the MapReduce framework, efficiently distributes large read-merely files equally cache needed by applications.
The Configuration Parameters
Nosotros can go job configuration options through surround variables. When we launch the MapReduce application, the framework will assign data to bachelor workers. Nosotros can access this data from our scripts. For example, if nosotros are running a mapper, then we can access the information about the file and slides nosotros are working on. Besides, we can get the data on whether we are running a mapper or reducer, which tin can be of import if we are running the aforementioned script on the map and reduce phase. We tin can also access task id within the map or reduce phase with the following surround variables: mapreduce_task_id, mapreduce_task_partition.
The Configured Parameters are localized in the job configuration for each task's execution. During the execution of a streaming job, the names of the "mapred" parameters are transformed. The dots (.) becomes underscores (_). For example, mapreduce.chore.id becomes mapreduce_job_id. In your code, use the parameter names with the underscores.
Updating status in streaming applications:
A streaming process can use the stderr to emit status information. To set a condition reporter:status:<message> should be sent to stderr.
Bundled Mappers, Reducers, and Partitions
Hadoop MapReduce comes bundled with a library of by and large useful mappers, reducers, and partitioners.
Hither are some related interesting stories that y'all might find helpful:
- Distributed Data Processing with Apache Spark
- Apache Cassandra — Distributed Row-Partitioned Database for Structured and Semi-Structured Data
Gain Access to Expert View — Subscribe to DDI Intel
guzmancomillonall.blogspot.com
Source: https://medium.datadriveninvestor.com/the-why-and-how-of-mapreduce-17c3d99fa900
0 Response to "Hadoop Streaming Read Number of Reducers Getenv"
Enregistrer un commentaire